서비스 개발자를 위한 Databricks 입문
Databricks를 처음 접하면 제품 이름이 아니라 플랫폼의 경계가 어디까지인지부터 헷갈린다. 데이터 레이크인지, 웨어하우스인지, Spark 실행 환경인지, 아니면 AI 플랫폼인지 한 번에 다 섞여 보이기 때문이다.
이 글은 서비스와 백엔드 개발자 관점에서 Databricks를 이해하기 위한 큰 그림 정리다. 데이터 엔지니어가 아니더라도, 운영 중인 서비스가 데이터 플랫폼과 어떻게 맞물리는지 파악해야 할 때가 있다. 그때 알아야 하는 최소한의 개념을 Lakehouse, Unity Catalog, Delta Lake, Serving Endpoints를 중심으로 한 흐름 안에서 정리한다.
왜 서비스 개발자도 Databricks를 알아야 하는가
서비스 팀이 Databricks를 직접 쓰지 않더라도, 어느 순간에는 데이터 플랫폼과 인터페이스를 설계하게 된다. 예를 들어 이벤트를 어디에 적재할지, 어떤 권한으로 데이터에 접근할지, 정제된 데이터를 API나 앱에서 어떻게 다시 가져올지를 결정해야 한다.
이때 필요한 것은 Databricks의 모든 기능을 깊게 아는 것이 아니라, 이 플랫폼이 어떤 계층으로 문제를 나눠 푸는지를 이해하는 일이다. 그래야 “이건 저장 문제인가, 권한 문제인가, 처리 문제인가, 서빙 문제인가”를 구분할 수 있다.
서비스 개발자에게 Databricks는 보통 “분석팀 도구”가 아니라 데이터 플랫폼과 맞닿는 인터페이스다. 어떤 계층이 무엇을 담당하는지 알면 협업 비용이 크게 줄어든다.
예전의 빅데이터 스택과 지금은 무엇이 다른가
Databricks를 이해하려면 먼저 “예전 빅데이터 플랫폼이 어떤 식으로 구성되었는가”를 떠올려 보는 편이 좋다. 과거에는 저장, 처리, 쿼리, 워크플로우, 권한 관리가 서로 다른 제품으로 강하게 분리되어 있는 경우가 많았다.
예를 들어 한 시대의 전형적인 스택은 이런 식이었다.
- 저장: HDFS, S3 같은 파일 스토리지
- 처리: Hadoop MapReduce, 이후 Spark
- SQL: Hive, Presto, Impala
- 워크플로우: Oozie, Airflow
- 거버넌스: Ranger, Sentry, 별도 메타스토어
이 구조는 각 계층이 분리되어 있어서 유연하다는 장점이 있었지만, 실제 운영에서는 여러 문제가 따라왔다. 같은 데이터를 여러 계층으로 복제하게 되고, 배치 처리와 SQL 분석 계층의 메타데이터가 어긋나고, 권한 체계가 엔진마다 조금씩 달라지는 경우가 흔했다.
클라우드로 넘어오면서 오브젝트 스토리지가 중심이 되고, 데이터 레이크와 데이터 웨어하우스가 함께 쓰이는 패턴이 확산됐다. 다만 이 단계에서도 원시 저장 계층과 분석 계층이 완전히 같은 시스템은 아니었기 때문에, 정제와 복제, 권한, 성능 최적화가 여전히 여러 조각으로 나뉘어 관리되는 일이 많았다.
그래서 최근 플랫폼은 “저장과 분석을 얼마나 자연스럽게 한 흐름으로 묶을 수 있는가” 쪽으로 발전해 왔다. Databricks가 이야기하는 Lakehouse는 바로 이 진화의 결과물로 이해하면 된다. 완전히 새로운 개념이라기보다, 예전 빅데이터 플랫폼에서 오래 불편했던 지점을 줄이려는 방향에 가깝다.
Databricks 이전과 이후를 아주 거칠게 비교하면
| 관점 | 예전 빅데이터/분리형 스택 | Databricks 같은 Lakehouse 접근 |
|---|---|---|
| 저장과 분석 관계 | 원시 저장과 분석 계층이 자주 분리된다 | 같은 저장 계층 위에서 정제와 분석을 이어 간다 |
| 메타데이터와 권한 | 엔진별로 따로 관리되기 쉽다 | 중앙 거버넌스 계층으로 모으려 한다 |
| 배치와 스트리밍 | 별도 파이프라인이 되기 쉽다 | 같은 데이터 자산 위에서 함께 다루려 한다 |
| 데이터 복제 | 용도별 중복 저장이 자주 생긴다 | 계층은 나누되 자산은 더 일관되게 유지하려 한다 |
| AI/서빙 연결 | 분석 시스템 바깥에서 다시 이어 붙인다 | 데이터와 모델 소비 계층을 더 가깝게 둔다 |
Databricks를 기능별로 나누어 보면
입문 단계에서 가장 헷갈리는 지점 중 하나는 Databricks가 “한 가지 도구”처럼 보이면서도 실제로는 여러 작업 영역을 함께 제공한다는 점이다. 저장, 처리, 분석, 거버넌스, ML/AI, 앱 연동을 각각 따로 보지 않으면 전체 그림이 잘 안 잡힌다.
| 영역 | 대표 기능 | 서비스 개발자 관점에서 보면 |
|---|---|---|
| 저장 | Delta Lake, Volumes | 원시 데이터와 정제 데이터를 어떤 자산으로 관리할지 정하는 계층 |
| 처리 | Spark, Jobs, Streaming | 배치 적재, ETL, 스트리밍 파이프라인을 돌리는 계층 |
| 분석 | Databricks SQL, Dashboards | 운영 지표나 분석 결과를 SQL과 BI로 보는 계층 |
| 거버넌스 | Unity Catalog, Lineage, Access Control | 누가 어떤 데이터를 보고 쓸 수 있는지 정하는 계층 |
| ML/AI | MLflow, Feature/Model lifecycle, Model Serving | 모델 학습 결과를 관리하고 추론 API로 연결하는 계층 |
| 앱/연동 | Databricks Apps, Delta Sharing | 데이터와 모델을 앱이나 외부 소비자에게 연결하는 계층 |
이렇게 보면 Databricks는 단순한 Spark 실행 환경이 아니다. 데이터를 저장하는 곳이면서, 정제하는 곳이고, 권한을 관리하는 곳이며, 필요하면 SQL 분석과 앱 소비까지 이어지는 플랫폼이다.
Databricks가 푸는 문제와 Lakehouse의 큰 그림
전통적인 데이터 시스템은 보통 두 갈래로 나뉘었다. 원시 데이터를 싸게 쌓아 두는 데이터 레이크와, 정제된 데이터를 SQL로 분석하는 데이터 웨어하우스다. 문제는 이 둘을 따로 운영하면 데이터 복제, 권한 관리 분산, 스키마 불일치, 처리 파이프라인 복잡도가 빠르게 커진다는 점이다.
Databricks는 이 간극을 줄이기 위해 Lakehouse라는 모델을 앞세운다. 저장은 개방형 파일 포맷과 오브젝트 스토리지를 활용하면서도, 처리와 거버넌스, SQL 분석, AI 워크로드를 하나의 플랫폼 위에서 연결하려는 접근이다.
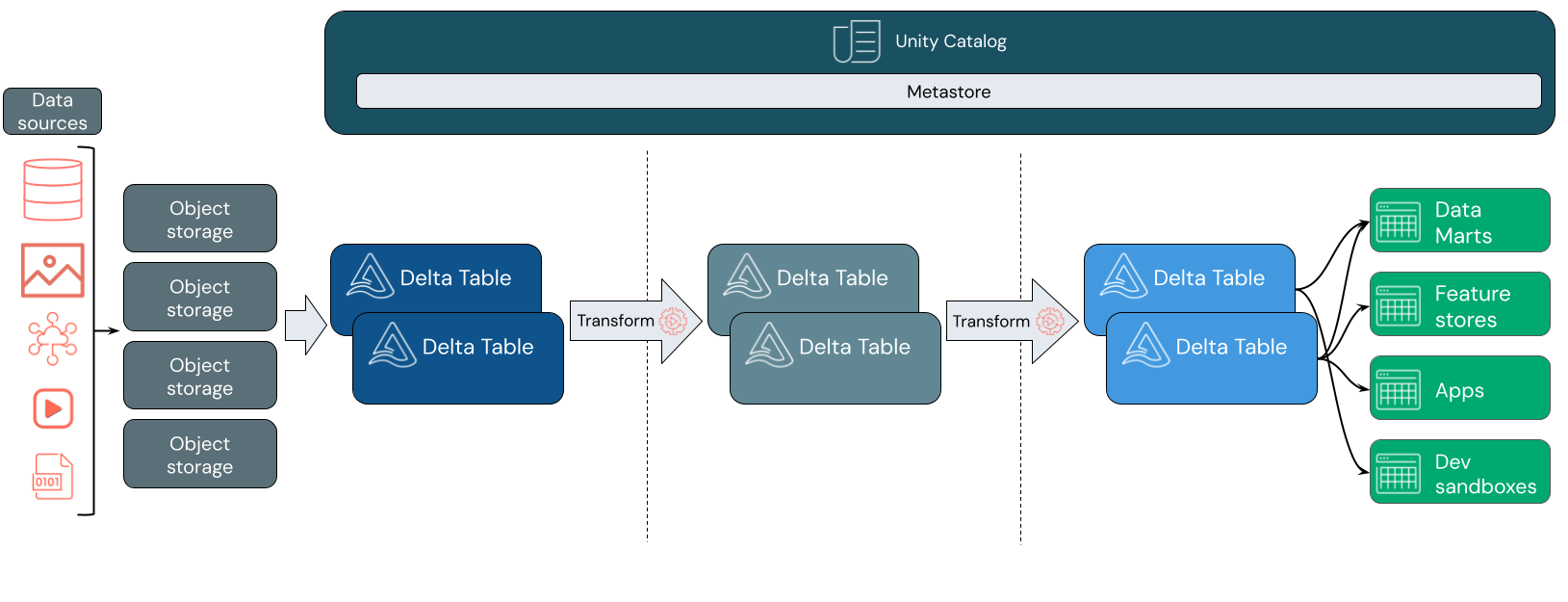
참고: 위 이미지는 Databricks 공식 문서의 Lakehouse 아키텍처 개요다. 출처: What is a data lakehouse?
핵심은 하나의 저장 계층 위에 여러 사용 방식이 겹친다는 점이다. 배치 처리, 스트리밍 처리, SQL 분석, 데이터 공유, 모델 서빙이 완전히 분리된 제품처럼 움직이지 않고, 같은 자산을 다른 방식으로 활용할 수 있게 만든다.
데이터 레이크, 웨어하우스, Lakehouse는 무엇이 다른가
Lakehouse를 이해하려면 기존 두 모델과 비교해 보는 것이 가장 빠르다.
| 접근 | 강점 | 한계 | Databricks에서 연결되는 요소 |
|---|---|---|---|
| 데이터 레이크 | 원시 데이터 저장이 유연하고 저렴하다 | 스키마 관리, 트랜잭션, 권한 체계가 약해지기 쉽다 | 오브젝트 스토리지, Delta Lake |
| 데이터 웨어하우스 | SQL 분석과 성능 최적화가 좋다 | 원시 데이터 처리와 다양한 워크로드 수용이 제한될 수 있다 | Databricks SQL |
| Lakehouse | 원시 저장과 분석 계층을 하나의 흐름으로 연결한다 | 거버넌스와 운영 규칙을 제대로 설계해야 한다 | Delta Lake + Unity Catalog + SQL/AI 워크로드 |
Lakehouse가 자동으로 문제를 해결해 주는 것은 아니다. 오히려 하나의 플랫폼으로 모아 놓았기 때문에, 카탈로그 구조, 권한 모델, 데이터 정제 계층 같은 운영 규칙을 더 일찍 정의해야 한다.
Unity Catalog는 데이터를 어떻게 통제하는가
Databricks를 이해할 때 가장 먼저 잡아야 하는 거버넌스 축이 Unity Catalog다. Unity Catalog는 단순한 테이블 목록이 아니라, 데이터와 AI 자산을 어떤 단위로 관리하고 누가 무엇을 볼 수 있는지 통제하는 중심 계층이다.
보통 서비스 개발자가 처음 마주치는 구조는 catalog -> schema -> table/view/volume/model 계층이다. 이 구조를 알면 팀 간 데이터 경계를 어떻게 나눌지, 읽기 권한과 쓰기 권한을 어디에 줄지 이야기할 수 있다.
참고:
catalog는 가장 바깥 경계이고,schema는 그 안에서 도메인이나 애플리케이션 단위로 자산을 묶는 하위 공간이라고 생각하면 이해가 쉽다.
Unity Catalog가 중요한 이유는 세 가지다.
- 권한을 데이터 자산 단위로 명확하게 줄 수 있다.
- 데이터 리니지와 감사 추적을 한곳에서 볼 수 있다.
- 여러 워크스페이스를 쓰더라도 거버넌스 기준을 중앙에서 유지할 수 있다.
이 계층을 제대로 이해하지 못하면, 서비스 팀은 보통 “테이블 권한은 받았는데 왜 접근이 안 되지?” 같은 문제를 만나게 된다. 실제로는 상위 카탈로그나 스키마 접근 권한이 빠진 경우가 많다.
아주 단순한 예시로 보면 권한 부여는 이런 식으로 생각할 수 있다.
GRANT USE CATALOG ON CATALOG analytics TO `data_app`;
GRANT USE SCHEMA ON SCHEMA analytics.audit TO `data_app`;
GRANT SELECT ON TABLE analytics.audit.events TO `data_app`;이 예시는 “테이블만 보이게 하면 끝”이 아니라, 카탈로그와 스키마 경계까지 함께 열어야 실제 접근이 가능하다는 점을 보여 준다.
Delta Lake가 저장 계층에서 해 주는 일
Delta Lake는 Databricks Lakehouse의 저장 계층에서 핵심 역할을 맡는다. 단순한 파일 저장이 아니라, 트랜잭션 로그를 기반으로 데이터 변경 이력을 관리해 테이블처럼 다룰 수 있게 만든다.
서비스 개발자 관점에서 특히 중요한 포인트는 아래 네 가지다.
| 기능 | 왜 중요한가 | 서비스 개발자 관점의 의미 |
|---|---|---|
| ACID 트랜잭션 | 중간 실패 시 깨진 상태를 줄인다 | 적재 중 일부만 반영된 데이터 문제를 줄인다 |
| Schema enforcement/evolution | 스키마 변화와 품질을 통제한다 | 이벤트 필드가 늘어날 때 파이프라인을 더 안정적으로 바꿀 수 있다 |
| Time travel | 특정 시점 데이터를 다시 볼 수 있다 | 분석 결과 검증, 복구, 재현에 유리하다 |
| Batch + Streaming 통합 | 동일 저장 계층에서 여러 처리 방식을 쓴다 | 운영 데이터와 분석 파이프라인의 연결이 단순해진다 |
특히 감사 로그, 주문 이벤트, 행동 이벤트처럼 시간이 지나면서 필드가 조금씩 늘어나는 데이터에서는 schema evolution과 재처리 가능성이 중요하다. 단순 CSV 적재와 달리, 나중에 해석 방식을 바꾸더라도 원본과 정제 단계를 다시 다루기 쉽다.
예를 들어 Delta Lake 테이블을 만든다고 생각하면 개념 예시는 이렇게 볼 수 있다.
CREATE TABLE IF NOT EXISTS audit_events_bronze (
event_id STRING,
event_time TIMESTAMP,
payload STRING
)
USING DELTA;그리고 서비스 개발자가 자주 보는 쿼리는 대개 이렇게 단순한 집계에서 시작한다.
SELECT
date_trunc('DAY', event_time) AS event_date,
count(*) AS event_count
FROM audit_events_bronze
GROUP BY 1
ORDER BY 1 DESC;이 정도 예시만 있어도 Databricks가 추상적인 플랫폼이 아니라, 결국은 테이블을 만들고 데이터를 적재하고 SQL로 소비하는 구조라는 감각을 주기 좋다.
Serving Endpoints는 언제 등장하는가
Databricks를 저장과 분석 플랫폼으로만 생각하면 Serving Endpoints가 갑자기 튀어나오는 기능처럼 보일 수 있다. 하지만 데이터와 모델을 같은 플랫폼에서 관리한다는 관점으로 보면 자연스럽다.
Serving Endpoints는 학습된 모델이나 외부 모델 접근을 실시간 API 형태로 제공하는 계층이다. 서비스 팀이 이 기능을 직접 쓰는 경우는 보통 아래처럼 나뉜다.
- 배치 분석 결과를 넘어서 실시간 추론이 필요한 경우
- 내부 애플리케이션이나 대시보드에서 모델 응답을 바로 호출해야 하는 경우
- RAG, 분류, 이상 탐지 같은 기능을 API로 노출해야 하는 경우
중요한 점은 Serving Endpoints가 Databricks 전체를 대표하는 기능은 아니라는 것이다. 많은 팀은 먼저 저장, 정제, 권한 구조를 안정화한 뒤에야 서빙 계층으로 넘어간다. 그래서 입문 단계에서는 “이 플랫폼이 모델까지 이어질 수 있다” 정도를 이해하면 충분하다.
실시간 소비 계층의 감각을 잡는 아주 간단한 예시는 다음처럼 볼 수 있다.
import requests
response = requests.post(
"https://<workspace-host>/serving-endpoints/<endpoint-name>/invocations",
headers={"Authorization": "Bearer <token>"},
json={"inputs": [{"text": "suspicious admin activity"}]},
timeout=30,
)
print(response.json())실제 운영 코드는 인증, 재시도, 오류 처리, 비밀정보 주입까지 더 필요하지만, 입문 단계에서는 “저장된 데이터와 학습된 모델이 결국 이런 식으로 애플리케이션 소비 계층에 연결된다” 정도를 이해하면 충분하다.
서비스 개발자는 어디까지 알면 충분한가
모든 팀이 Databricks 내부를 깊게 알아야 하는 것은 아니다. 다만 아래 질문에 답할 수 있을 정도는 되어야 협업이 쉬워진다.
- 우리 서비스는 어떤 데이터를 어떤 형식으로 전달하는가
- 그 데이터는 어떤 카탈로그와 스키마 경계 안에서 관리되는가
- 누가 읽고 누가 쓸 수 있는가
- 정제된 결과를 대시보드, SQL, 앱, 모델 중 어디에서 소비하는가
이 관점에서 보면 Databricks는 “데이터팀만 쓰는 도구”가 아니라, 서비스의 운영 데이터가 장기 분석, 거버넌스, AI 활용으로 이어지는 경로를 제공하는 플랫폼이다.
처음 보면 특히 헷갈리는 용어들
| 용어 | 처음 들으면 헷갈리는 이유 | 이렇게 이해하면 쉽다 |
|---|---|---|
| Workspace | 작업 공간인지 권한 경계인지 모호하다 | 사용자가 일하는 실행 환경이지만, 거버넌스는 Unity Catalog와 함께 봐야 한다 |
| Metastore | 예전 Hive 개념과 겹쳐 보인다 | Unity Catalog 메타데이터와 권한의 상위 컨테이너라고 보면 된다 |
| Catalog | 데이터베이스와 비슷해 보여 혼동된다 | 더 상위의 도메인 경계다 |
| Delta Lake | 제품인지 포맷인지 헷갈린다 | 트랜잭션 로그를 가진 테이블 저장 계층으로 보면 된다 |
| Serving Endpoints | 앱 기능인지 모델 기능인지 모호하다 | 실시간 추론이나 모델 API 노출 계층이다 |
처음 학습할 때는 Lakehouse 전체를 한 번에 이해하려고 하기보다 아래 순서가 편하다.
- Lakehouse와 저장 구조를 먼저 이해한다.
- Unity Catalog로 권한과 경계를 본다.
- Delta Lake로 데이터 변경과 정제를 본다.
- 마지막에 SQL, Apps, Serving 같은 소비 계층을 본다.
Databricks를 볼 때 남겨야 할 기준
Databricks의 모든 기능을 외울 필요는 없다. 대신 저장, 거버넌스, 처리, 서빙이 어떤 경계로 나뉘는지를 잡아 두는 것이 중요하다. 그 경계만 이해해도 서비스 개발자는 데이터 플랫폼과 이야기할 수 있는 언어를 얻게 된다.
다음 글에서는 이 큰 그림 위에서 Databricks Apps를 운영 환경에 배포할 때 인증을 어떻게 설계해야 하는지 이어서 본다. 개인 토큰으로 시작한 실험을 프로덕션 구조로 바꿀 때, Service Principal과 secret manager, Unity Catalog 권한 설계가 왜 같이 움직여야 하는지를 정리할 예정이다.